Networker

NetWorker (ehemalig Legato) ist ein leistungsfähiges und trotzdem einfach bedienbares System zur Sicherung, Archivierung, Migration und Rekonstruktion von Datenbeständen heterogener Rechnerumgebungen. Es ermöglicht sowohl die vollautomatische und routinemässige Bearbeitung von Datenbeständen der beteiligten Systeme als auch ereignisgesteuerte und individuell von den beteiligten Systemen aus angestossene Aktionen. Mit NetWorker lässt sich ein hochverfügbare Sicherungsumgebung mit redundanten NetWorker-Servern aufbauen. Konfigurationsdaten werden von den Servern gemeinsam verwaltet und genutzt. Die Datensicherung und -wiederherstellung; sie ist automatisch und zeitgesteuert oder manuell anstossbar oder ereignisgesteuert möglich. Alle UNIX-, Linux-, Windows- und NetWare-Dateisysteme können gesichert werden, die Online-Sicherung von Datenbanken wie MSSQL, ORACLE (auch auf NetApp), INFORMIX, DB2 ist verfügbar. Es werden Gesamt-, Differenz-, inkrementelle und die synthetische Gesamtsicherung unterstützt. Die Sicherungsdaten können noch auf dem Client vor ihrer Übertragung auf das Sicherungsmedium komprimiert oder verschlüsselt werden. Verschlüsselungen oder Komprimierungen werden beim Restaurieren automatisch wieder rückgängig gemacht. Während der Übertragung zum Sicherungsmedium werden parallel Einträge im Online-Katalog erzeugt, die den schnellen Zugriff auf die verschiedenen Versionen der Sicherungsdaten bei einem späteren Restore komfortabel möglich machen.
Inhaltsverzeichnis
- 1 Software Module:
- 2 Restore
- 3 FAQ
- 3.1 savegroup Gruppe starten
- 3.2 Starten und stoppen des NetWorkers
- 3.3 Direktiven - Directives
- 3.4 Backup Workflow per CLI starten
- 3.5 Debug auf Client einschalten
- 3.6 NT Service in SQL als User einbinden
- 3.7 VM Client aus Imagebased Gruppe entfernen, wenn der Client bereits gelöscht wurde
- 3.8 Device für Replikation-Mtrees (Subfolders) einrichten
- 3.9 Stage - Stageing
- 3.10 Bulk import of clients
- 3.11 Start einer Gruppe vom Client aus
- 3.12 Networker Server filesystem full 100%
- 3.13 Einrichten Exadata
- 3.14 Duration
- 3.15 mminfo
- 3.16 TapeLibrary
- 3.17 VSS
- 3.18 Logs
- 3.19 Notifications - Mails
- 3.20 Lizenzen
- 3.21 Exchange Modul Befehle
- 3.22 Sicherungs Methoden
- 3.23 Bootstrap Sicherung
- 3.24 Reports
- 3.25 Retention und/oder Browstime verlängern
- 3.26 SaveSets löschen
- 3.27 savepnpc
- 3.28 Daten und Logs sammeln für ein CALL
- 3.29 "No full backups of this save set were found in the media database; performing a full backup"
- 3.30 Auf einen anderen Client restoren
- 3.31 Authentifizierungsmethoden ändern
- 3.32 Zertifikat löschen
- 3.33 Zertifikat löschen - Conflicting NSR peer information resources detected for host
- 3.34 Alle Zertis löschen
- 3.35 user administrator on machine (machine_name) is not in administrator list
- 3.36 Mgmt Console startet nicht mehr
- 3.37 Volumes können nicht mehr gemountet werden
- 3.38 Client von BackupLAN auf ServerLAN umstellen
- 3.39 UsrClass.dat(.LOG) konnte nicht gesichert werden
- 3.40 Fibrechannel Check mit NetWorker
- 3.41 Networker Server filesystem full 100%
- 3.42 Status Symbol im Monitoring auf Grün setzen
- 3.43 Client - keine Verbindung
- 3.44 User auf BackupServer hinzufügen
- 3.45 User erfassen
- 3.46 nsrget
- 3.47 Retention und/oder Browstime verlängern
- 3.48 Jobs DB neu erstellen
- 4 Failed Client
- 4.1 Disk Consolidation
- 4.2 Job failed weil falscher Pfad - The base volume for the path ... is unavailable or offline
- 4.3 The base volume for the path [PFAD] is unavailable or offline
- 4.4 87359:save: No FRN for
- 4.5 DisasterRecovery - Suppressed xx bytes (WMI)
- 4.6 Keine Sicherung läuft mehr
- 4.7 Networker Server reagiert nicht mehr
- 4.8 SAP HANA stoppt beim Queuing
- 4.9 VMware Error disabling storage migration for virtual machine "xxx"
- 4.10 SAP HANA DB's aufnehmen
- 4.11 Restore
- 4.12 Kontrolle Log
- 5 Links
Software Module:
NW - NetWorker Client
NMDA - NetWorker-Module-for-Databases-and-Applications
NMM - NetWorker-Module-for-Microsoft
NMSAP - NetWorker-Module-for-SAP-with-Oracle
VBA VProxy
Restore
FAQ
savegroup Gruppe starten
savegroup -G DI_DB_HDS_SQL_EH4_2W_Mo-Sa_0000_2 -g -I &
Starten und stoppen des NetWorkers
Stop
nsr_shutdown
Start
/etc/init.d/networker start
Direktiven - Directives
- Anleitung für die Clientseitige Erstellung von Direktiven
forget Forgetallinheriteddirectives(those starting with a "+" in parent directories).
ignore Ignore subsequent .nsr files found in descendent directories.
allow Allow .nsr file interpretation in descendent directories.
Linux direktiven
Beispiel:
<< / >> +skip : core skip : tmp temp
<< /usr/spool/mail >> mailasm : *
<< /nsr >> allow
Windows direktiven
Beispiel:
<< C:\ >> +skip : *.tmp *.img skip : tmp *.sys
<< D:\MSQL Databases\MSSQL\Backuptemp>> skip : *.* +skip : test*.*
<< D:\MSQL Databases\MSSQL\Data >> +skip : *.mdf +skip : *.ldf
Backup Workflow per CLI starten
nsrworkflow -p [POLICY_NAME] -w [WORKFLOW_NAME] -A "[ACTION_NAME] -l full" -a&
Beispiel:
[root@hbeh05 ~]# nsrworkflow -p FS_EV_ZF -w FB_2W_So_0400 -A "FullBackup -l full" -a&
Optional: Angabe welche Clients zu sichern sind wenn nicht die ganze Gruppe laufen soll mit "-c [Clientname]:[SaveSet]", mehrere Clients durch Komma trennen
[root@hbeh05 ~]# nsrworkflow -p FS_EV_ZF -w FB_2W_So_0400 -A "FullBackup -l full" -c v04ug4.pnet.ch:All,v056lf.pnet.ch:All-mounts -a&
Debug auf Client einschalten
save -vvv -D3
NT Service in SQL als User einbinden
sc sidtype nsrexecd unrestricted
Status abfragen:
sc qsidtype nsrexecd
Anschliessend kann es sein dass noch der SQL Server neu gestartet werden muss.
VM Client aus Imagebased Gruppe entfernen, wenn der Client bereits gelöscht wurde
Es kann passieren, dass eine VM bereits abgebaut wurde, aber noch in einer Imagebased Gruppe von uns vorkommt.Den Fehler sieht man, wenn man die Gruppen in der Policies übersicht öffnet und anschliessend im Workflow runs einen Faild Status hat und dann mit "Show Action" und "Get Full Log" eine solche oder ähnlche Fehlermeldung vorfindet."Unable to find selected VM work item with UUID "50237303-702f-1e7b-76ef-8056974c5968" in vCenter, the work item will be skipped."
Um die VM aus der Gruppe endgültig zu löschen muss folgdens auf dem entsprechenden NetWorker Server ausgeführt werden.
nsrpolicy group update vmware -g gruppen_name -O UUID
Beispiel für die zwei VMs oben
nsrpolicy group update vmware -g VM_DCP2_EH_IF_2W_Mo-So_0200 -O vm-22960 nsrpolicy group update vmware -g VM_DCP4_ZF_IF_4W_Mo-So_0200 -O 50237303-702f-1e7b-76ef-8056974c5968
Das Ganze ist auch unter https://emcservice.force.com/CustomersPartners/kA2f1000000RMnOCAW beschrieben.
Device für Replikation-Mtrees (Subfolders) einrichten
Beispiel für das eh4_fs_bak_dev2 Device/Folder:

1. Zuerst den Replikationsfolder ausfindig machen:

2. Device für den Replikationsfolder erstellen. Dazu muss natürlich eine Storagenode der Gegenstelle angegeben werden und es muss auf read-only gesetzt sein:

Danach noch den ddBoost user als remote user eintragen:

3. Im Pool, an welchen das Device eh4_fs_bak_dev2 angehängt ist, das neue Replikationsdevice unter "Selection Criteria" hinzufügen:

4. Danach noch mounten und das Device ist über den Pool eh4_fs_bak bzw. dasselbe Volume wie das eh4_fs_bak_dev2 erreichbar:
![]()
Stage - Stageing
nohup nsrstage -F -b -m -S -f &
z.B.
nohup nsrstage -F -b go2_ora_bak -m -S -f /root/input.txt&
Bulk import of clients
Instead of adding clients manually one at a time in the NMC, you can perform an initial bulk import.
nsradmin -i bulk-import-file
where the bulk-import-file contains many lines like this
create type: NSR Client;name:w2k8r2;comment:SOME COMMENT;aliases:w2k8r2,w2k8r2-b,w2k8r2.cyberfella.co.uk;browse policy:Six Weeks;retention policy:Six Weeks;group:zzmb-Realign-1;server network interface:backupsvrb1;storage nodes:storagenode1b1;
Use excel to form a large csv, then use Notepad++ to remove commas. Be aware there is a comma in the aliases field, so use an alternative character in excel to represent this then replace it with a comma once all commas have been removed from the csv.
Start einer Gruppe vom Client aus
nsradmin -s server_name nsradmin> . type: nsr group; name: group name nsradmin> update autostart: start now
[neuenschwank@vnix1a ~]$ nsradmin -s hbeh01
NetWorker administration program.
Use the "help" command for help, "visual" for full-screen mode.
nsradmin> . type: nsr group; name:Manual_FS_EH4_1W_Kurt_1
Current query set
nsradmin> update autostart: start now
autostart: start now;
Update? yes
updated resource id 99.0.101.171.0.0.0.0.93.166.43.84.127.0.0.2(1646)
nsradmin>
Scann Needed, Appendable
Es kommt vor das ein Disk Volume die Meldung "Scann Needed, Appendable", im Menupunkt Mode, anzeigt.
Falls dies der Fall ist muss jedes Device welches auf dieses Volume schreibt gescannt werden. Dies kann nur gemacht werden, wenn keine Sicherung auf das Volume schreibt, da die Devices nur ungemounted gescannt werden können.
Auf dem Backuperver in der NMC die Properties öffnen und im Register "Setup" im Feld "Administrator" zusätzlich *@* eintragen. Nun auf dem jeweiligen Device bitte das Auto MediaManagment ausschalten. anschliessend auf dem jeweiligen StorageNode oder Backupserver, an welchem das Device hängt folgendes ausführen.
Unmounted des Devices
nsrmm -vv -u -s Backup-Server -f Devicename
Scannen des Devices
scanner -vv -s Backup-Server Devicename
Stellen des Volume Names auf "nicht zu scannen"
nsrmm -vv -s Backup-Server -o notscan eh4_Volumenam
Mounten des Devices
nsrmm -vv -m -s Backup-Server -f Devicename
Auto MediaManagment, auf dem Device welches gescannt wurde, wieder einschalten.Mit allen weitern Devices welche zum selben Volume gehören ebenso verfahren. Wenn alle Devices gescannt und wieder gemounted *@* wieder entfernen.
Networker Server filesystem full 100%
Wenn der NW Server auf dem root Verzeichnis zu 100% voll ist, mache folgendes:
hbeh01:~ # df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 8.1G 8.1G 0 100% / udev 16G 332K 16G 1% /dev tmpfs 16G 0 16G 0% /dev/shm /dev/sda1 518M 53M 466M 11% /boot /dev/sda3 8.1G 1.6G 6.5G 20% /var /dev/sda4 8.1G 1.1G 7.0G 14% /home /dev/sda5 4.1G 33M 4.0G 1% /tmp /dev/sda6 243G 12G 232G 5% /opt /dev/mapper/vg_index-lv_index 2.0T 918G 1.1T 45% /nsr/index /dev/mapper/vg_logs-lv_logs 171G 11G 160G 6% /nsr/logs /dev/mapper/vg_mm-lv_mm 205G 35M 204G 1% /nsr/mm /dev/mapper/vg_res-lv_res 137G 38G 99G 28% /nsr/res /dev/mapper/vg_tmp-lv_tmp 239G 95G 144G 40% /nsr/tmp hbeh01:~ #
und nun dies:
hbeh01:/ # find /nsr \( -name index -o -name logs -o -name mm -o -name res -o -name tmp \) -prune -o -type f -mtime -1 -size +1k -exec ls -ltrh {} \;
-rw------- 1 root root 1.8G Apr 25 12:00 /nsr/cores/nsrjobd/nsrjobd.04.25.16
-rw------- 1 root root 2.1G May 05 12:00 /nsr/cores/nsrjobd/nsrjobd.06.05.16
-rw------- 1 root root 2.3G Aug 30 12:00 /nsr/cores/nsrjobd/nsrjobd.08.30.16
-rw------- 1 root root 88K Aug 30 12:02 /nsr/cores/nsrvba_save/core
hbeh01:/ #
Lösche nun alle nsrjobd.xx.xx.xx Dateien bis auf die neuste Version. Dies wäre in diese, Beispiel nsrjobd.08.30.16
Wenn du Glück hast läuf der NetWorker Service wieder, ansonsten muss er neu gestartet werden.
Viel Glück
Einrichten Exadata
Bei Exadata Nodes muss zusätzlich zur Standard Einrichtung eines Linux / Oracle Clients noch folgendes gemacht werden:
- Auf dem Hauptbackupserver in der NMC die Properties öffnen und im Register "Setup" im Feld "Administrator" zusätzlich pro Node ein Eintrag wie folgt erstellen
oracle@[NODENAME].[DOMÄNE]
zB: Kurt@* Thomas@* Jennifer@* oracle@hz01db01.pnet.ch oracle@hz01db02.pnet.ch oracle@hz01db03.pnet.ch oracle@hz01db04.pnet.ch
Duration
Sicherungsdauer eines Savesets rausfinden
- mminfo -vq "client=hzff02,ssid=[SSID]" -r "ssid,name,sscreate(20),sscomp(20)"
hbeh01:~ # mminfo -vq "client=hzff02,ssid=697843964" -r "ssid,name,sscreate(20),sscomp(20)" ssid name ss created ss completed 697843964 /vol/vol_hnas05_02 07/04/15 22:24:28 07/05/15 02:03:26 hbeh01:~ #
- dann noch ausrechenen Start- zu Endzeit
mminfo
Praktische Abfragen
- SSID rausfinden
mminfo -q client=hosp25,level=full -r 'ssid(53)',totalsize,name,ssid,volume
TapeLibrary
Befehle
inquire
Zeigt die SAN Geräte wie auch die Library und das Drive an
nsrjb -HEvv
Tape auswerfen
jbconfig
Configtool zum einrichten einer TapeLibrary
VSS
Auf dem Client nicht mit VSS sichern!
Ins Feld "Client Properties" - "Apps & Modules" - "Save operations" folgendes eintragen:
VSS:*=off
oder falls der VSS Dienst nicht eingeschaltet ist (viel bei MSSQL Servern):
VSS:DISASTER_RECOVERY=off
Logs
Log Files ansehen
in der konsole:
nsr_render_log [LOGFILE] zb: nsr_render_log daemon.raw
.raw in .log
nsradmin -p nsrexecd nsradmin> vioben im Register auf [EDIT] type: NSR log; administrator: "isroot,host=hbeh01.pnet.ch", "user=root,host=h001nr.pnet.ch", "user=root,host=localhost"; owner: NetWorker; maximum size MB: 2; maximum versions: 10; runtime rendered log: /nsr/logs/daemon.log; runtime rollover by size: Enabled [Disabled]; runtime rollover by time: ; name: daemon.raw; log path: /nsr/logs/daemon.raw;mit ESC in Resgiter [QUIT] Enternsradmin verlassen mit q
Änderungs History
Änderungen die von NetWorker admins gemacht wurden
less /nsr/logs/rap.logNach
etwas suchen
vi /nsr/logs/rap.log
dann
ESCAPE / NSR Client
Editor verlassen mit ESC
:q
Notifications - Mails
Die Mails können wie folgt konfiguriert werden:
/bin/mail -s "[Betreff]" [Empfänger Adresse], [weitere Empfänger Adresse]
Standart von NetWorker:
/bin/mail -s "h05zbb.pnet.ch's savegroup failure" root
Beispiel
/bin/mail -s "Tomaten Suppe" kurt.neuenschwander@post.ch, root@nashornserver.ch
Lizenzen
Licence expired
Wenn eine oder mehrere Lizenzen plötzlich ein AblaufDatum haben obwohl sie eigentlich en "never expired" haben sollten, mache folgendes
- gehe in die NetWorker MMC
- zum Tab Configuration
- links im Menü "Registrations"
- öffne die Lizenz "NETWORKER SOURCE CAPACITY 10TB LICENSE" und kopiere folgendes ins Feld Auth Code: 4e0421f1 oder neu 416731b0
- das selbe für die Lizenz "NetWorker Source Capacity Data Zone Enabler" : a3dbf34a oder neu 602cacc5
- Voila
45-Day Evaluation Enabler Codes + installieren
- Enabler Code aus der Lizenzliste im Ordner "Backupinfrastruktur Betrieb" Register 3 aussuchen
- In der NetWorker Administration eine neue Registration eröffnen
- Name: *** (trägt nach Abschluss der Eingabe automatisch den richtigen Namen der Lizenz ein!)
- Comment: Test-Lic. [Datum] + (evt. [Tier])
- Enabler Code: [Code aus Lizenzliste]
Die 45 Tages Lizenz kann nochmal um 45 Tage verlängert werden (funktioniert nur ein mal!)
- In der NetWorker Administration die zu verlängernde Test- Registration(Lizenz) öffnen
- Eingabe:
- Auth code: [-]
- mit OK bestätigen und das Expiration Datum erhöht sich um nochmal 45 Tage.
Übersicht der aktuellen Lizenzierung
Um eine Übersicht der aktuellen Lizenzierung in der Firma zu zeigen:
- Einloggen auf Backup-Server1
- Command Box öffnen
Befehl: nsrlic Option: -v zeigt noch eine Liste der "Connected Clients"
Export für monatliches Review: nsrlic > \\fileablage\licences_legato.txt ... prüfen und anschliessend ITS Assistant informieren.
Exchange Modul Befehle
Die Exchangesicherung kann in verschidene Jobs aufgeteilt werden.
z.B.:
- Information Store
- Mailboxes
- Public Foldes
Die werden mittels Befehl im NetWorker "Save set:" aufgeteilt.
| Was | Code |
|---|---|
| Information Store | MSEXCH:IS |
| Mailboxes | MSEXCH:MB |
| Public Foldes | MSEXCH:PF |
Bei einem aufsplitten in einzelne Mailboxen oder Public Folders können die Pfade angesetzt werden.
z.B.
MSEXCH:MB
MSEXCH:MB/mailbox
MSEXCH:MB/mailbox/folder/
MSEXCH:MB/mailbox/folder/subject_line
MSEXCH:MB/Muster,Hans
MSEXCH:PF
MSEXCH:PF/folder_tree/folder/
MSEXCH:PF/folder_tree/folder/subject_line
MSEXCH:PF/Public Folders/Firma/
MSEXCH:IS
MSEXCH:IS/storage_group
MSEXCH:IS/storage_group/database
MSEXCH:IS/First Storage Group/Large Mailbox Store
Es können auch Textfilebasierte Listen die auf dem Client liegen eingelesen werden. Den Befehl erfolgt durchden "Backup command:"
z.B.: nsrxchsv.exe -I Tesxt.txt oder nsrxchsv.exe -I include_PF.txt
Fehler bei Exchange Sicherung
Falls ein oder mehrere Server mit einem Fehler beendet werden, mitte unbedingt die Details des Fehlers genau anschauen. Falls der Fehler darauf hinweist, dass im EventLog ein Fehler vorhanden ist wie um Beispiel unten. Hilft wenn man mit dem Exchange Verantwortlichen zusammen das EventLog löscht. Anschliessend geht die Sicherung des Servers wieder.
024176 ERROR:Terminating this job because there is a -1022 error in the eventlog (Event ID 481). A log file in H:\DAGP01\LogPost037\ may be corrupt. Repair or restore the file before restarting this job. Check the event in the application event log on HXMB15 for more information.
Sicherungs Methoden
Dieser Abschnitt gilt nicht für Full BackUp.
Die Überprüfung der zu sichernden Daten z.B. bei einem inkrementellen BackUp von einem Client, kann auf zwei verschiedene Arten/Methoden durchgeführt werden.
Archivbit Methode
Standard im Networker ist die Überprüfung des Archivbit's. Daten auf dem Client die neu erstellt oder geändert werden, erhalten automatisch vom OS das Attribut A (Archive). Sichert der Networker die Dateien, entfernt er das Attribut auf dem Filesystem. So weiss er bei der nächsten z.B. inkrementellen Sicherung welche Daten er sichern muss und welche er überspringen kann.
LastWriteTime und CreateTime Methode
Bei dieser Methode vergleicht der Networker die Daten nach Datum "Erstellt" (Create Time) und nach dem Datum "Geändert" (Modified). Stimmen die Daten mit der letzten Sicherung überein, überspringt er die Datei ansonsten sichert er sie.
Die Archivbit Methode ist ca. 15% schneller als die andere. Hat aber den Nachteil, dass bei Dateien die gerade geöffnet und/oder benutzt werden, das Archivbit nicht entfernt werden kann. Der Networker meldet das anschliessend als Fehler!
- Einstellungen der Methoden
Es wird auf dem Client eine Systemvariable gesetzt:
- Für Archivbit:
NSR_AVOID_ARCHIVE NO oder keine Variable
- Für LastWriteTime and CreateTime:
NSR_AVOID_ARCHIVE YES

Nach dem Setzen der Variable muss noch der "NetWorker Remote Exec Service" neu gestartet werden.
Diese Informationen stammen von Zusammentragungen aus dem Internet und eigenen Tests. Es ist leider in den Handbüchern von EMC nicht dokumentiert (sonst bitte melden).
Bootstrap Sicherung
Die Bootstraps (Liste der Savesets vom BackupServer) müssen vorhanden sein, damit der BS selber in einem Disaster Fall wiederhergestellt werden kann. Unsere Bootstraps werden 1 Mal pro Tag in E-Mail Form an die interne Backup Mailbox sowie an unseren Support-Dienstleiter gesendet, was uns die Sicherheit gibt, unabhängig von der Exchange Infrastruktur diese Information immer verfügbar zu haben.
Reports
Deduplizierungsrate auf DataDomain
Reports - DataDomain Statistics - Save Set Details
Duration Time (Sicherungsdauer) von einzelnen Clients
Gewünschtes Resultat:
- Duration Time (Sicherungsdauer) von einzelnen Clients
Report Auswahl:
Reports - Networker Backup Statistics - Save Set Details
oder
Sicherungsdauer eines Savesets rausfinden
- mminfo -vq "client=hzff02,ssid=[SSID]" -r "ssid,name,sscreate(20),sscomp(20)"
hbeh01:~ # mminfo -vq "client=hzff02,ssid=697843964" -r "ssid,name,sscreate(20),sscomp(20)" ssid name ss created ss completed 697843964 /vol/vol_hnas05_02 07/04/15 22:24:28 07/05/15 02:03:26 hbeh01:~ #
- dann noch ausrechenen Start- zu Endzeit
Retention und/oder Browstime verlängern
Um die browsable- und retentiontime eines SaveSets zu verlängern, muss die SaveSetID (SSID) bekannt sein. Nicht vergessen dass meistens mehrere SSID benötigt werden (full und incremental Backup).
Ändern der Retentiontime/Browsetime:
- Einloggen auf Backup-Server1
- Subsystem Device Driver Management öffnen
Eingabe: nsrmm -S [ssid] -w [Datum] -e [Datum]
Beispiel; verlängert die beiden Zeiten (brows und retention) auf den 20.05.2009: nsrmm -S 7894561263 -w 05/20/2009 -e 05/20/2009
Kontrolle:
Eingabe: mminfo -c [Client] -q [Bedingung] -r [Ausgabe]
Beispiel Eingabe: mminfo -c server1 -q ssid=1234567890 -r"ssid,ssbrowse,ssretent"
Beispiel Ausgabe: ssid browse retent 1234567890 20.05.2009 20.05.2009
SaveSets löschen
gehe auf den BS hbeh01 ins Verzeichnis /nsr/scripts
löschen der alten ssid's
rm ss_ids
die neuen ssid's in Liste abfüllen
vi ss_ids
Löschscript ausführen
./delete_ssids.sh
wenn fertig noch folgendes ausführen (dauert ca 15 min.)
nsrim -X
Nun sollte es auch auf der DD im Cleaningbereich sichtbar sein
savepnpc
Der Backup Command savepnpc
...er ermöglicht Pre- und Postscriptprocessing.
Damit können vor und nach einer Sicherung Programme oder Skripts ausgeführt werden.
Ein Anwendungsbeispiel wäre die Offlinesicherung einer Datenbank: Vor der Sicherung die Datenbank per Skript stoppen, dann sichern, und anschliessend die Datenbank per Skript wieder hochfahren.
Tip: Verwendet man diesen Backupcommand, so gibt es ein eigenes Logfile im ../nrs/logs Verzeichnis: savepnpc.log. Darin werden auch Meldungen/Fehler von den Pre- und Postcommands mitgeschrieben.
savepnpc und ../nsr/res/<Gruppenname>.res
Nach einmaligem Starten der Gruppe, in der der Client ist, wird am Client ist das <Gruppenname>.res File erzeugt. In diesem File werden die Pre- und Postcommands sowie zwei Parameter eintragen.
|
Inhalt .res File: type: savepnpc; precmd: "echo hello"; postcmd: "echo bye"; timeout: 12:00:00; abort precmd with group: No;
|
|
!!! Wichtig !!!
In einem res File muss am Ende der Eingaben unbedingt ein
Enter (Carriage Return) eingefügt werden! Ansonsten fliegt der BackupJob auf die Schnautze! :P
- nice to know
- Mit dem optionalen Parameter timeout wird die Zeit definiert, zu der spätestens mit der Ausführung des Post-Commands begonnen wird.
Hierdurch können Sie sicherstellen, dass eine Anwendung zu einem bestimmten Zeitpunkt wieder zur Verfügung steht.
- Kann ein Pre-Backup Script nicht fehlerfrei durchgeführt werden, wird der Rest des ganzen Prozesses abgebrochen.
- Das Ergebnis der Pre- und Post-commands wird in der Datei ...\nsr\res\savepnpc.log am NetWorker Client gespeichert.
Beispiele
res Files
server12 mit oracle Datenbank:
type: savepnpc; precmd: "D:\\oracle\\ora10g\\BIN\\sqlplus sys/***@rmandb as sysdba @D:\\oracle\\admin\\rmandb\\scripts\\db_stop.sql"; pstcmd: "D:\\oracle\\ora10g\\BIN\\sqlplus sys/***@rmandb as sysdba @D:\\oracle\\admin\\rmandb\\scripts\\db_start.sql"; timeout: "01:30pm"; abort precmd with group: No;
Beispiel mit mehreren Script- Aufrufen:
type: savepnpc; precmd: "c:\\scripts\\rsa-db-backup.bat", "c:\\scripts\\start-bla-script.bat", "c:\\scripts\\start-bli-script.bat", "c:\\scripts\\start-ble-script.cmd", "c:\\scripts\\start-blu-script.bat"; pstcmd: "c:\\scripts\\rsa-db-backup_close.bat", "c:\\scripts\\stop-bla-script.bat", "c:\\scripts\\stop-bli-script.bat", "c:\\scripts\\stop-ble-script.bat", "c:\\scripts\\stop-blu-script.bat"; timeout: "12:00:00"; abort precmd with group: No;
Logging
Zusätzlich wurde teilweise noch das - durch das res File - aufgerufene Script mit einer logging Funktion erweitert.
backup_getItemDsetFile.cmd ;
@@echo off @rem -- Script zum generieren einer Item/File Liste für SingleFile Restore @ echo ---------------------START------------------------- >> D:\backup_getItemDsetFileListe.log echo script backup_getItemDsetFile.cmd started @ %date% %time% >> D:\backup_getItemDsetFileListe.log
D:\oracle\ora10g\BIN\sqlplus infodba/infodba@ypsprod1 @D:\ugs\admin\sqlGetItemDsetFileListe.sql
echo script backup_getItemDsetFile.cmd end @ %date% %time% >> D:\backup_getItemDsetFileListe.log
Logfile auf D:\
---------------------------------------------- script backup_getItemDsetFile.cmd started @ 06.11.2007 11:57:24.69 script backup_getItemDsetFile.cmd end @ 06.11.2007 11:57:36.23 ---------------------------------------------- script backup_getItemDsetFile.cmd started @ 07.11.2007 11:57:23.54 script backup_getItemDsetFile.cmd end @ 07.11.2007 11:57:24.03
Daten und Logs sammeln für ein CALL
- Auf dem Orion01 einloggen
LW E:\ ist eine Batchdatei die die wichtigsten Daten zusammenfasst und in ein ZIP File kopiert.
- Achtung! Im Patchfile zuerst noch "Client_name" und "Group_Name" ändern
Call Logs zusammen kopieren.bat
Berut auf einer Call Anfrage:
Das support Call und Problematik mit den SYSTEM DB Backup wird unten "Call #1234" bearbeitet werden. Für weitere Analyse Ich bitte Sie um zu Sendung von folgendes:
Von Backup server aus:
- Networker Resource Dateien --> (...\nsr\res\*.*)
- Networker log Dateien --> (...\nsr\logs\*.*)
- mminfo Syntax Output für betroffenen Klient
# mminfo -av -q "client=<CLIENT NAME>" -r
"client
,name
,ssid
,savetime(22),ssflags,sumflags,level,volume,sumsize,nfiles,nsavetime"
- Das savegrp Output von Kommando Zeile:
# savegrp -vvv -D 1 -l full -c <CLIENT_NAME> -G <GROUP_NAME> >
savegrp.out 2>&1
"No full backups of this save set were found in the media database; performing a full backup"
Symptom: die Meldung "No full backups of this save set were found in the media database; performing a full backup" erscheint beim Backup von SAP virtuellen Instanzen. Dies ist nicht korrekt, wenn INCR als Backup Level gesetzt wurde, sollte auch INCR gebackuped werden!
Erklärung: der Backup referenziert nicht mehr sauber auf den Namen der virtuellen Instanz. Deswegen erkennt er den SaveSet nicht und initiiert einen neuen FULL Backup.
Behebung: Man muss die legato services auf den physischen ClusterNodes neu starten.
Auf einen anderen Client restoren
z.B. eine Datei von einem server01 Backup auf den server02 restoren.
In der config des Source- Clients (server01) im Register Globals (2 of 2) ins Feld "Remote access:" server02.corp.itsroot.biz
Authentifizierungsmethoden ändern
Standard sind in der Firma die beiden Auth.Methoden "nsrauth" und "oldauth" in gebrauch
nsrauth für die Server mit NetWorker 7.3.*
oldauth für die Server mit NetWorker 7.2.*
Zum Ändern auf dem BS die CMS öffnen:
nsradmin -p nsrexec NetWorker administration program. Use the "help" command for help, "visual" for full-screen mode. nsradmin> . type: NSRLA (note: there is a blank space between . and type) Current query set nsradmin> show auth methods nsradmin> print auth methods: "0.0.0.0/0,nsrauth/oldauth"; nsradmin> update auth methods: "0.0.0.0/0,oldauth" auth methods: "0.0.0.0/0,oldauth"; Update? yes updated resource id 3.0.156.101.198.4.188.67.137.69.101.64(137) nsradmin> print auth methods: "0.0.0.0/0,oldauth"; nsradmin> quit
Zertifikat löschen
Funktioniert leider im GUI nicht!!!
mit der CMD folgendes auf dem BS durchführen:
nsradmin -p nsrexec nsradmin> delete type:NSR peer information
type: NSR peer information; administrator: Administrators,"group=Administrators,host=serverbk"; name: client; peer hostname: client; Change certificate: ; certificate file to load: ; Delete? y
sieht z.B. für "server1" so aus:
nsradmin> delete type:NSR peer information
type: NSR peer information;
administrator: "group=Administrators,host=localhost",
"group=Administrators,host=Backup-Server01-fqdn",
"domäne,host=Backup-Server01", "domäne,host=Backup-Server02",
"user=Administrator,host=Mgmt-Server-fqdn";
name: server1-fqdn;
peer hostname: server1-fqdn;
Change certificate: ;
certificate file to load: ;
Delete? y
Zertifikat löschen - Conflicting NSR peer information resources detected for host
Fehler tritt auf wenn es ein Zertifikatproblem zwischen dem NetWorker Server oder der NetWorker Management Console und einem Client gibt.Für die Lösung des Problems muss das Zertifikat auf dem NetWorker Server oder der NetWorker Management Console für den entsprechenden Client gelöscht werden.Das Zertifikat wird bei der nächsten Verbindung mit dem Client wieder neu generiert.
Achtung!: Meistens muss mann es auf dem Backupserver und dem MOVED TO... vbnmc1 machen!
Für das Löschen des Zertifikats müssen folgende Befehle ausgeführt werden:
hbhk99:~ # nsradmin -p nsrexecd NetWorker administration program. Use the "help" command for help, "visual" for full-screen mode. nsradmin> nsradmin> hbhk99:~ # nsradmin -p nsrexecd -s h066gx.pnet.ch -C -y "nsr peer information"
... oder ...
nsradmin -p nsrexec print type:nsr peer information; name:client_name delete y
Bsp. Zertifikat auf dem NetWorker Server für den Client v04ug4.pnet.ch löschen:
hbeh01:~ # nsradmin -p nsrexec
NetWorker administration program.
Use the "help" command for help, "visual" for full-screen mode.
nsradmin> print type:nsr peer information; name:v04ug4.pnet.ch
type: NSR peer information;
administrator: root, "user=root,host=hbeh01.pnet.ch";
name: v04ug4.pnet.ch;
peer hostname: v04ug4.pnet.ch;
Change certificate: ;
certificate file to load: ;
nsradmin> delete
type: NSR peer information;
administrator: root, "user=root,host=hbeh01.pnet.ch";
name: v04ug4.pnet.ch;
peer hostname: v04ug4.pnet.ch;
Change certificate: ;
certificate file to load: ;
Delete? y
deleted resource id 1.0.234.108.76.0.0.0.202.211.112.83.127.0.0.2(1)
nsradmin>
Alle Zertis löschen
- auf Backupserver mit root einlogen
- nsradmin -p nsrexecd
- vi
- --> dann zu 'Select' navigieren
- --> anschliessend zu 'NSR peer information'
- --> jetzt auf 'Delete' und anschliessend die Enter- Taste solange halten bis alle gelöscht sind.
dies sieht in etwa so aus:
hbeh01:~ # nsradmin -p nsrexecd NetWorker administration program. Use the "help" command for help, "visual" for full-screen mode. nsradmin> nsradmin> nsradmin> nsradmin> vi Command: Select [Next] Prev Edit Create Delete Options Quit 1 of 422 (on hbeh01.pnet.ch)
type: NSR log;
administrator: root, "user=root,host=hbeh01.pnet.ch";
owner: NMC Log File;
maximum size MB: 2;
maximum versions: 10;
runtime rendered log: ;
runtime rollover by size: Enabled [Disabled];
runtime rollover by time: ;
name: gstd.raw;
log path: /opt/lgtonmc/logs/gstd.raw;
Command: [Select] Next Prev Edit Create Delete Options Quit Select a resource type to be displayed.
type: NSR auditlog NSR log [NSR peer information] NSR remote agent NSR system port ranges NSRLA
Command: Select Next Prev Edit Create [Delete] Options Quit 1 of 408 (on hbeh01.pnet.ch)
type: NSR peer information;
administrator: *@*, Administrator, "isroot,host=hbeh01.pnet.ch", root, SYSTEM@vbnmc1.pext.ch, "user=root,host=hbeh01.pnet.ch",
"user=root,host=localhost";
name: hcwe9i.pnet.ch;
peer hostname: hcwe9i.pnet.ch;
Change certificate: Load certificate from file Clear certificate ;
certificate file to load: ;
Nun noch die Zertis auf dem NMC Server löschen
- Öffne die NMC Console und gehe in die 'Configuration'
- Im linken Baum öffne die 'Lochal Hosts'
- Gehe zum NMC Server (hier vbnmc1.pext.ch) --> Doppelklick - Jetzt sollten sehr viele Zertis angezeigt werden
- Nun mit [Control]+[A] alles auswählen und mit [Del] alle löschen
- Voila.
...flls hier die Meldung "user administrator on machine (machine_name) is not in administrator list" kommt, bitte nächsten Abschnit machen und anschliessend diesen hier wiederholen.
user administrator on machine (machine_name) is not in administrator list
- Öffne die CMD als Administrator auf dem NMC Server
- Lokal in den Client einlogen mit: nsradmin -s vbnmc1.pext.ch -p nsrexec
C:\Program Files\EMC NetWorker\nsr\bin>nsradmin -s vbnmc1.pext.ch -p nsrexec NetWorker administration program. Use the "help" command for help. nsradmin> nsradmin> nsradmin> nsradmin> . type: nsrla Current query set nsradmin> nsradmin> nsradmin> show administrator nsradmin> nsradmin> nsradmin> print administrator: "group=Administrators,host=localhost", "group=Administrators,host=vbnmc1.pext.ch", "isroot,host=hbeh01", "isroot,host=hbeh01.pnet.ch", "isroot,host=hbhk99"; nsradmin> nsradmin> nsradmin> nsradmin> update administrator: administrator,"group=Administrators,host=localhost", "group=Administrators,host=vbnmc1.pext.ch", "isroot,host=hbeh01", "isroot,host=hbeh01.pnet.ch", "isroot,host=hbhk99"; administrator: administrator, "group=Administrators,host=localhost", "group=Administrators,host=vbnmc1.pext.ch", "isroot,host=hbeh01", "isroot,host=hbeh01.pnet.ch", "isroot,host=hbhk99"; Update? y updated resource id 2.0.168.28.80.0.0.0.52.52.86.83.172.27.34.18(71) nsradmin> nsradmin> . type: nsrla Current query set nsradmin> show Administrator nsradmin> print administrator: administrator, "group=Administrators,host=localhost", "group=Administrators,host=vbnmc1.pext.ch", "isroot,host=hbeh01", "isroot,host=hbeh01.pnet.ch", "isroot,host=hbhk99"; nsradmin>
Mgmt Console startet nicht mehr
Nach der User- und Passworteingabe kommte ca 1 min später eine Fehlermeldung: "Could not authenticate user name and password, try again!"
Dies bedeutet, dass das Java Applet nicht mehr auf die Mgmt Console connecten kann.
WORKAROUND 1
Try this first:
- stop the EMC GST service
- then look for any instance of a 'dbsrv9.exe' process and kill it.
- start the GST service
- try to login via NMC
WORKAROUND 2
- Aus zB. Neku1opr's-Profil auf Mgmt-Server den Ordner [Profil]\Application Data\Sun ins eigene Profil kopieren.
WORKAROUND 3
Hat Workaround 1&2 nicht geklappt?
In diesem Fall gibts nur noch folgendes;
- Eine Sicherheitskopie mit Hilfe von xcopy des Ordners D:\Legato anlegen
- Unter Add or Remove Programms > Click for support informations > die "NetWorker" Version notieren
- Unter Add or Remove Programms "NetWorker Management Console" deinstallieren
- Unter Add or Remove Programms "Java 2 Runtime Environment,..." deinstallieren (falls vorhanden noch alle Java Updates deinstallieren). Danach muss ein Reboot des Servers gemacht werden.
- Falls vorhanden den Ordner C:\Program Files\Java löschen (somit wird auch der Cache entfernt)
- Die gleiche Version der Mgmt Console wieder installieren. Installation ohne Java Runtime inst!
!!! Gehe dringend genau nach der Installationsanleitung vor und fülle das IQ/OQ Protokoll aus !!!
- Die Java Runtime 1.4.2_14 der NetWorker Version installieren. Keine Updates auf Version 6!
- Mit der URL http://mgmt-server-fqdn:9000/ die Konsolenverknüpfung starten.
Voila, die Verbindung sollte wieder klappen...!
Volumes können nicht mehr gemountet werden
Fehler: Waiting for x writable volumes...
Einfachste Variante ist die erste. Also bei Variante 1 beginnen und wenn nicht erfolgreich die nächste versuchen...
- Variante 1
- Das Volume öffnen
- Das Häckchen "Auto media management" entfernen und mit OK schliessen
- Auf das Volume mit der rechen Maustaste clicken und "Enable/Desable" auswählen
- Das Volume erneut öffnen und den Radio-Button "Enabled" auf "Yes" stellen.
- Das Häckchen "Auto media management" wieder einsetzen und mit OK schliessen
- Variante 2
- Die Netzwerkverbindung Backup-LAN2 des orion01 deaktivieren und nach einer min. wieder aktivieren.
- Die Volumes wieder mounten.
- Variante 3
- Ansonsten den server Backup-Sever01 rebooten
{BLOG} ...brachte es am 29.01.09 auch nicht zu stande! musste die DataDomain rebooten um die Devices wieder mounten zu können. Nach dem Reboot der DD musste ich noch den Dienst "NetWorker Backup and Recover Server" auf dem Backup-Server01 restarten. Anschliessend wurden die Devices wieder gemountet.
Client von BackupLAN auf ServerLAN umstellen
- Client
- Verzeichnis ...legato\res\ die datei SERVER mit Wordpad ändern.
- Backup-Server0*-fqdn
- Backup-Server0*-fqdn
- BakupLAN deaktivieren
- Shortcut ändern (b entfernen): -s Backup-Server1
b
- Verzeichnis ...legato\res\ die datei SERVER mit Wordpad ändern.
- Console
- Alias: ***.domäne löschen
- Server Network Interface: IP auf 192.168.11.11 umstellen
- Storage Nodes:
- Backup-Server0*.domäne
- Backup-Server0*.domäne
- Backup-Server1 + 2
- Hostfile Einträge des Servers löschen
UsrClass.dat(.LOG) konnte nicht gesichert werden
Das ist der User-Hive und kann nicht immer gesichert werden, weil nicht immer frei.
Heisst aber nicht, dass diese Datei nicht trotzdem gesichert wird. Legato macht da nicht immer saubere Angaben.
Darf nicht exkludiert werden, die Warning-Meldung darf aber ignoriert werden.
* <WARNING> : File C:\WINDOWS\system32\config\systemprofile\Local Settings\Application Data\Microsoft\Windows\UsrClass.dat could not be opened and was not backed up. (The process cannot access the file because it is being used by another process.) * <WARNING> : warning while saving C:\WINDOWS\system32\config\systemprofile\Local Settings\Application Data\Microsoft\Windows\UsrClass.dat * <WARNING> : File C:\WINDOWS\system32\config\systemprofile\Local Settings\Application Data\Microsoft\Windows\UsrClass.dat.LOG could not be opened and was not backed up. (The process cannot access the file because it is being used by another process.) * <WARNING> : warning while saving C:\WINDOWS\system32\config\systemprofile\Local Settings\Application Data\Microsoft\Windows\UsrClass.dat.LOG
Fibrechannel Check mit NetWorker
in Linux
wenn netWorker Installiert ist sollte als root dies da funktionieren.
inquire
sollte sowas ausgeben:
h05zbb:~ # inquire
(using name lookup)
scsidev@0.0.0:HP LOGICAL VOLUME 3.54|Disk, /dev/sg1
S/N: PCQVU0CRH4P11L
WWNN=600508B1001C5B1137E29E69D43D3E83
VBNN=00000000
scsidev@1.0.0:HP P220i 3.54|RAID Controller, /dev/sg0
S/N: PCQVU0CRH4P11L
VENN=PCQVU0CRH4P11L
VBNN=00000000
Networker Server filesystem full 100%
Wenn der NW Server auf dem root Verzeichnis zu 100% voll ist, mache folgendes:
hbeh01:~ # df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 8.1G 8.1G 0 100% / udev 16G 332K 16G 1% /dev tmpfs 16G 0 16G 0% /dev/shm /dev/sda1 518M 53M 466M 11% /boot /dev/sda3 8.1G 1.6G 6.5G 20% /var /dev/sda4 8.1G 1.1G 7.0G 14% /home /dev/sda5 4.1G 33M 4.0G 1% /tmp /dev/sda6 243G 12G 232G 5% /opt /dev/mapper/vg_index-lv_index 2.0T 918G 1.1T 45% /nsr/index /dev/mapper/vg_logs-lv_logs 171G 11G 160G 6% /nsr/logs /dev/mapper/vg_mm-lv_mm 205G 35M 204G 1% /nsr/mm /dev/mapper/vg_res-lv_res 137G 38G 99G 28% /nsr/res /dev/mapper/vg_tmp-lv_tmp 239G 95G 144G 40% /nsr/tmp hbeh01:~ #
und nun dies:
hbeh01:/ # find /nsr \( -name index -o -name logs -o -name mm -o -name res -o -name tmp \) -prune -o -type f -mtime -1 -size +1k -exec ls -ltrh {} \;
-rw------- 1 root root 1.8G Apr 25 12:00 /nsr/cores/nsrjobd/nsrjobd.04.25.16
-rw------- 1 root root 2.1G May 05 12:00 /nsr/cores/nsrjobd/nsrjobd.06.05.16
-rw------- 1 root root 2.3G Aug 30 12:00 /nsr/cores/nsrjobd/nsrjobd.08.30.16
-rw------- 1 root root 88K Aug 30 12:02 /nsr/cores/nsrvba_save/core
hbeh01:/ #
Lösche nun alle nsrjobd.xx.xx.xx Dateien bis auf die neuste Version. Dies wäre in diese im Beispiel nsrjobd.08.30.16
Wenn du Glück hast läuf der NetWorker Service wieder, ansonsten muss er neu gestartet werden.
Viel Glück
Status Symbol im Monitoring auf Grün setzen
Funktioniert nicht bei Probinggroups
Auf dem BackupServer folgendes absetzen:
root werden
savegrp -vvv -p -G [GROUPNAME]
z.B.:
savegrp -vvv -p -G DI_FS_EH3_1W_Di+Do_2300_2_Slow
Client - keine Verbindung
Test vom Client auf den BackupServer
telnet hbeh01 7937
falls es klappt mit [Ctrl]+[5] wieder raus (Linux).
Die Portranges die offen sein müssen sind </ br>7937-7987</ br>8500-8999
dies kann mit folgendem Befehl getestet werden
nsrports
z.B.: hbhk99:~ # nsrports Service ports: 7937-7987 8500-8999 Connection ports: 0-0 hbhk99:~ #
Oder vom NW Server ein Client checken:
hbeh01:/home/networker # nsrports -s vsql07 Service ports: 7937-7987 8500-8999 Connection ports: 0-0 hbeh01:/home/networker #
falls es nicht überein stimmt, Ports folgendermassen neu konfigurieren:
nsrports – S 7937-7987 8500-8999
User auf BackupServer hinzufügen
nsraddadmin -u "user=administrator, host=hbli01.pnet.ch"
Um schnell einloggen zu können (zB. bei einem neuen Server) kann vorübergehend folgendes eingetragen werden. ALERT! Aber danach unbedingt wieder löschen
nsraddadmin -u "user=*, host=*"
User erfassen
- NMC starten
- Setup wählen
- Users and Roles --> Users navigieren
- Neuen User erstellen

- auf jedem NetWorker Backup Server der Name des Users folgendermassen hinzufügen

nsrget
nsrget is used to collect various logs and information about a Backup Client/Server. Sometimes EMC requests to send nsrget reports because of service requests.
\\hpcf09\it24$\IT244\03_Dokumentation\05_ZDS_NEU\02_Networker\04_Software\NetWorker 8.1.1 <-- nsrget Files are located here
Windows
- Copy nsrget.zip to target machine
- Extract zip archive
- Copy nsrget.bat to C:\Program Files\EMC NetWorker\nsr\bin\
- Copy all .nsrget Files to C:\Program Files\EMC NetWorker\nsr\util\
- Start Windows Management Instrumentation Service if it's not already running
- Execute nsrget.bat as administrator and follow prompt
Linux
- Copy nsrget.tar to target machine
- Extract files from tar archive
- Execute nsrget.sh
Retention und/oder Browstime verlängern
Um die browsable- und retentiontime eines SaveSets zu verlängern, muss die SaveSetID(SSID) bekannt sein. Nicht vergessen dass meistens mehrere SSID benötigt werden (full und incremental Backup).
Ändern der Retentiontime/Browsetime:
- Einloggen auf Backup-Server1
- Subsystem Device Driver Management öffnen
Eingabe:
nsrmm -S [ssid] -w [Datum] -e [Datum]
Beispiel; verlängert die beiden Zeiten (brows und retention) auf den 20.05.2009:
nsrmm -S 7894561263 -w 05/20/2009 -e 05/20/2009
Wenn der Fehler Cannot exceed the browse time of a recoverable save set 2289136780 kommt nur mit -e (Fehler kommt wenn browse time und Retention time nicht gleich sind)
Eingabe:
nsrmm -S [ssid] -e [Datum]
Beispiel: verlängert nur die Retention Zeit auf den 20.05.2009:
nsrmm -S 7894561263 -e 05/20/2009
Kontrolle:
Eingabe:
mminfo -c [Client] -q [Bedingung] -r [Ausgabe]
Beispiel Eingabe:
mminfo -c server1 -q ssid=1234567890 -r"ssid,ssbrowse,ssretent"
Beispiel Ausgabe:
ssid browse retent 1234567890 20.05.2009 20.05.2009
Um mehrere Save Sets zu verlängern, können all ssids in folgende Datei auf dem NetWorker Server Zeile für Zeile geschrieben werden:
/nsr/scripts/ss_ids
und dann kann folgendes Script ausgeführt werden:(ACHTUNG: Browse und Retention Time muss im Script noch angepasst werden):
/nsr/scripts/change_retention_time.sh
Jobs DB neu erstellen
Stoppen der Networker Services am Networker Server
nsr_shutdown
wechseln in den NW Install Pfad
cd /nsr/res/jobsdb
umbenennen der DB
mv jobsdb.db jobsdb.old
löschen des Inhaltes in /nsr/tmp
/nsr/tmp # rm -r *.*
restart der NSR Services auf dem Networker Server
/etc/init.d/networker start
Failed Client
Disk Consolidation
Falls VMs die im Imagebased Backup immer wieder failen und den Status „…need disk consolidation“ haben, bitte folgende Massnamen mit den VM Admins durchführen:
- In seltenen Fällen können die VM Jungs einfach die Disk Consolidation machen und es funktioniert wieder.
- Meistens muss ein Storage vMotion gemacht werden(zwei Mal… hin und her) damit das Backup wieder funktioniert.
- Wenn auch dies nicht hilft, muss nach dem vMotion nochmal ein Disk Consolidation gemacht werden (obwohl die Meldung „…need disk consolidation“ nicht mehr angezeigt wird).
- Falls dies auch nicht funktionieren würde, müsste der Server heruntergefahren und gecloned werden. Dann den Clone starten und mit ihm weiter arbeiten…gem. Sommer Daniel.
Ist vielfach bei Clustern der Fall. Sicherung schlägt fehl weill NW denkt er habe noch ein Laufwerk auf dem Client zum sichern (z.B. LW M:\). Aus irgend einem Grund ist dies nicht mehr angehängt. Nun meldet NW Backuperror (z.B.: saveD:\ fail. The base volume for the path [m:\oracle\i7w\dbtools] is unavailable or offline. ) obwohl er kein M: mehr hat.
Lösung:
File mit dem Namen pathownerignore (ohne Dateiendung) unter dem Verzeichniss ..\EMC NetWorker\nsr\bin erstellen und Service neu starten. Bei Clustern immer auf allen Clusternodes einfügen lassen.
Mail an Serverbetrieb:
Hallo Könnt ihr auf den Servern [Clusternode1] und [Clusternode2] ein File mit dem Namen pathownerignore (ohne Dateiendung) unter dem Verzeichniss ..\EMC NetWorker\nsr\bin erstellen und den NetWorker Remote Excec Service neu starten? Merci Gruess
Beispielmeldung:
88224:save: The base volume for the path [h:\ipec\program files\ipecfilemover] is unavailable or offline. Please ensure all volumes are online for backup operations. 88222:save: Could not add [h:\ipec\program files\ipecfilemover\ipecfilemoverservice.exe] for backup. WINDOWS ROLES AND FEATURES: ERROR: VSS failed to add components in pre save, writer=System Writer: The system cannot find the file specified. (Win32 error 0x80070002) 98193:save: Unable to save the SYSTEM STATE save sets: cannot add all the system state writers to the snapshot. 94693:save: The backup of save set 'K:\IPEC\Data' failed. c0584f.pext.ch:K:\IPEC\Data: retried 3 times.
Dies Problem tritt ua. bei MS 2008 SR2 auf.
Lösung:
Mail an Serverbetrieb, IT245
Hallo Wir haben Backupprobleme wegen eines bekannten MS Problems KB 980794(https://support.microsoft.com/en-us/kb/980794) Bitte auf ALLEN Clusternodes des Servers [ClusterServername zb c056**] folgendes in der Registry erstellen: 1. Type regedit in the Search programs and files box, and then press ENTER. If you are prompted for an administrator password, type the password. If you are prompted for confirmation, provide confirmation. 2. Locate and then click the following registry subkey: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SystemWriter Note If this registry subkey does not exist, please create it manually. 3. On the Edit menu, point to New, and then click Multi-String Value. 4. Type ExcludedBinaryPaths, and then press ENTER. Note 5. Right-click ExcludedBinaryPaths, and then click Modify. 6. In the Value data box, type all binary paths that should be excluded from the system state backup operation, and then click OK. Note The binary paths should be absolute paths. They should not include environment variables (such as %windir%) and should not be enclosed in double or single quoation marks. Zum Bispiu so: h:\ipec\program files\ipecfilemover 7. Exit Registry Editor. 8. Nun den „NetWorker Remote Exec Service" neu starten. Das wars schon. Bitte ein Feedback geben wenn alle Nodes gemacht sind. Besten Dank zum Voraus
Wenn das nicht hilft, gibt es noch eine weitere Lösung.
Hallo zusammen Der Server <Servername> hat Probleme mit dem Backup. Bitte folgende Schritte durchführen. 1. Right click on "My Computer" (or "This PC") and select "Properties". 2. Advanced System Settings. 3. Click on "Environment Variables". 4. On "System Variables" create the following variable: NSR_INITIALIZE_DIRECTIVE Variable Value: TRUE 5. Click OK to create the variable. This may require a node restart. 6. Review the following registry key: HKLM\SYSTEM\CurrentControlSet\Control\SystemWriter\ReportWin32ServicesNonSystemState If it is not set to 1, then set it to 1. NOTE: On Windows 2012 R2 this registry key doesn't seem to exist. If this key is not present, the default value is 1, so there is no further action needed.
87359:save: No FRN for
Error Message:
87359:save: No FRN for C:\Users\. 87359:save: No FRN for C:\Users\All Users\.
Win2012
Kindly find the command below to deactivate the Change Journal on a Windows Server 2012 Standard x64 Edition:
fsutil usn deletejournal /D C:
Win2008
Please try the following and see if the problem goes away.Disable the Change Journal on the C: drive in Networker and see if the problem goes away.
Remove the check mark for the C: drive.

DisasterRecovery - Suppressed xx bytes (WMI)

Detailmeldung:

Lösung:
"Windows Management Instrumentation" Dienst starten und Startmodus auf Automatisch einstellen.
CauseWindows Change Journal was activated on the client.At times the Windows OS will change the File Reference Number while NetWorker is attempting to backup the file in question.
ResolutionDeactivate"Windows Change Journal" on the client.ORIf a backup of the folder is not required, create a directive and skip the affected folder backup.Skip the directory path via a directive. For Example:>skip: "Network Associates"ORThis could be an intermittent issue and the next backup might work correctly.
NotesBy default on Windows 2000, 2003, XP an NTFS volume will have its CJ (Change Journal) disabled.
On Vista and Windows 2008, the Change Journal is active by default.Any application can activate or disable the volume's journal at any time but note that on Vista and Windows 2008, if the Change Journal is deactivated, it is automatically reactivated by the system.
Keine Sicherung läuft mehr
- gehe auf den BS und siehe welche dienste laufen
ps -ef | grep nsr
das müsste etwa so aussehen:
root 611 24839 0 Jul23 ? 00:00:02 /usr/sbin/nsrmmd -b 2 -N 524206081 -n 7 -s hbmu01.pnet.ch -t hbmu01.pnet.ch root 17442 24051 0 09:39 ? 00:00:28 /usr/sbin/nsrdisp_nwbg root 22526 24839 0 Jul24 ? 00:00:01 /usr/sbin/nsrmmd -b 2 -N 524206081 -n 3 -s hbmu01.pnet.ch -t hbmu01.pnet.ch root 22821 24839 0 Jul24 ? 00:00:01 /usr/sbin/nsrmmd -b 2 -N 524206081 -n 8 -s hbmu01.pnet.ch -t hbmu01.pnet.ch root 23958 1 0 Jul23 ? 00:01:08 /usr/sbin/nsrexecd root 23995 1 0 Jul23 ? 00:02:09 /usr/sbin/nsrd root 24014 23995 0 Jul23 ? 00:07:58 /usr/sbin/nsrmmdbd root 24030 23995 0 Jul23 ? 00:00:00 /usr/sbin/nsrindexd root 24051 23995 0 Jul23 ? 00:00:00 /usr/sbin/nsrdispd root 24071 23995 0 Jul23 ? 00:03:57 /usr/sbin/nsrjobd root 24299 23958 0 Jul23 ? 00:07:50 /usr/sbin/nsrlogd root 24468 23995 0 Jul23 ? 00:00:23 /usr/sbin/nsrvmwsd root 24839 23958 0 Jul23 ? 00:16:28 /usr/sbin/nsrsnmd -s hbmu01.pnet.ch -M 655 -n 524206081 -N 1 root 25500 24839 0 Jul23 ? 00:00:03 /usr/sbin/nsrmmd -b 2 -N 524206081 -n 5 -s hbmu01.pnet.ch -t hbmu01.pnet.ch root 25501 24839 0 Jul23 ? 00:00:03 /usr/sbin/nsrmmd -b 2 -N 524206081 -n 6 -s hbmu01.pnet.ch -t hbmu01.pnet.ch root 32321 23995 0 Jul24 ? 00:00:00 /usr/sbin/nsrcpd root 63630 7348 0 11:02 pts/1 00:00:00 grep nsr
Wichtig ist der nsrvmwsd Prozess! wenn der nicht läuft sieht es etwa so aus:
hbmu01:/nsr/res # ps -ef | grep nsr root 23958 1 1 14:51 ? 00:00:00 /usr/sbin/nsrexecd root 23995 1 1 14:51 ? 00:00:00 /usr/sbin/nsrd root 24014 23995 1 14:52 ? 00:00:00 /usr/sbin/nsrmmdbd root 24030 23995 0 14:52 ? 00:00:00 /usr/sbin/nsrindexd root 24051 23995 1 14:52 ? 00:00:00 /usr/sbin/nsrdispd root 24071 23995 7 14:52 ? 00:00:00 /usr/sbin/nsrjobd root 24299 23958 1 14:52 ? 00:00:00 /usr/sbin/nsrlogd root 24373 7348 0 14:52 pts/1 00:00:00 grep nsr
... und das ist unschön.
- nun mit /etc/init.d/networker stop und anschliessend /etc/init.d/networker start den NetWorker neu starten.
- kommt nach einigen Minuten der nsrvmwsdnicht hoch:
- kontrolliere das Servers file mit vi /nsr/res/serversda müsste jetzt der BackupServer drinn stehen. z.B. hbmu01.pnet.ch
- wenn nicht, der richtige einfügen und die Servises neu starten
Networker Server reagiert nicht mehr
Wenn ein Networker Server nicht mehr reagiert (z.B. auf der Management Konsole der Ladebalken bei 33% stehen bleibt), ist folgendes zu tun:
- Auf dem blockierten Networker Server via Putty einloggen.
- Den Networker Dienst stoppen --> /etc/init.d/networker stop
- Warten, bis alle Savesessions gestoppt sind --> ps -ef |grep save*
- Falls ein savegrp nicht mehr reagiert, diesen direkt abschiessen --> kill -9 *ProzessID*
- Parallel dazu auf allen angehängten Storage Nodes den Networker Dienst ebenfalls stoppen.
- Wenn keine Sessions mehr laufen (alternativer Befehl --> /etc/init.d/networker Status), den Networker Dienst zuerst auf dem blockierten Server, dann auf allen Storage Nodes, wieder starten -->
/etc/init.d/networker start.
- Falls der Networker Server immer noch nicht reagiert, muss der Stop&Start Vorgang zwei drei Mal wiederholt werden.
SAP HANA stoppt beim Queuing
Es kann passieren, dass SAP HANA Filesystem oder DB beim Queuing nicht mehr weiterläuft. Hier hilft folgendes:
- Client Einstellungen öffnen
- Unter Save Set nur /etc eingeben
- Client backupen lassen.

VMware Error disabling storage migration for virtual machine "xxx"
Wenn ein VMware Snapshot Backup katastrophal fehlgeschlagen ist kann es vorkommen das ein Storage vMotion Lock bestehen bleibt. Networker löscht dies dann nicht eigenmächtig, könnte ja zu Wartungszwecken gesetzt sein. Wenn sicher ist das es eine Hinterlassenschaft von Networker ist kann es manuell entfernt werden.
- Aus dem Backup-Log (Backup-Details -> SaveSet-> Show Messages -> Get Full Log) die Moref-ID der VM auslesen
"VmSpec": {
2017/03/28 07:33:05 NOTICE: [@(#) Build number: 82] "Name": "v04wu8",
2017/03/28 07:33:05 NOTICE: [@(#) Build number: 82] "VmMoref": "vm-1466",
2017/03/28 07:33:05 NOTICE: [@(#) Build number: 82] "VirtualDisks": [
- Auf passenden vProxy per SSH als root einloggen
cd /opt/emc/vproxy/bin source ../unit/vproxy.env ./vmconfig -c info -k "vm-name" -l moref -p ** -u username -v vcentername z.B.: ./vmconfig -c info -k "vm-1466" -l moref -p * -u s-zdsvba -v v000ow.pext.ch VM Config vCenter: "v000ow.pext.ch", User: "s-zdsvba", Password: "***", Lookup Mode: "moref", Lookup Key: "vm-1466", Command: "info" Logging into vCenter 'v000ow.pext.ch' Logged into vCenter 'v000ow.pext.ch'. Initialing Program structure for standalone program. Connected to session on vCenter 'v000ow.pext.ch' Version '6.0.0 build-3634794, API:6.0', Uuid:adbae30d-cd2a-4025-9645-ae46f4c43584. Searching for virtual machine with MORef "vm-1466" ... Querying vCenter for definition of virtual machine with MORef of "vm-1466" ... Found virtual machine "v04wu8" with MORef "vm-1466". vm-1466: Name: "v04wu8". vm-1466: CBT Enabled: true. vm-1466: Migration Enabled: false. vm-1466: Backup Locked: true. Disconnected from session on vCenter 'v000ow.pext.ch'. Logging out from vCenter 'v000ow.pext.ch' Logged out from vCenter 'v000ow.pext.ch'.
- Wenn Migration Enabled auf true steht ist irgendwas gröberes kaputt, dann muss VMAdmin Team genauere Analyse machen
- Wenn Migration Enabled auf false steht folgendes ausführen:
./vmconfig -c "enable-migration" -k "vm-name" -l moref -p ** -u username -v vcentername z.B.: ./vmconfig -c "enable-migration" -k "vm-1466" -l moref -p * -u s-zdsvba -v v000ow.pext.ch VM Config vCenter: "v000ow.pext.ch", User: "s-zdsvba", Password: "***", Lookup Mode: "moref", Lookup Key: "vm-1466", Command: "enable-migration" Logging into vCenter 'v000ow.pext.ch' Logged into vCenter 'v000ow.pext.ch'. Initialing Program structure for standalone program. Connected to session on vCenter 'v000ow.pext.ch' Version '6.0.0 build-3634794, API:6.0', Uuid:adbae30d-cd2a-4025-9645-ae46f4c43584. Searching for virtual machine with MORef "vm-1466" ... Querying vCenter for definition of virtual machine with MORef of "vm-1466" ... Found virtual machine "v04wu8" with MORef "vm-1466". Initializing VDDK... Initializing VDDK (6.0) in "/opt/emc/vproxy" using config "/opt/emc/vproxy/conf/VixDiskLib.config" and logging to "/opt/emc/vproxy/runtime/logs/vmconfig/vmconfig-vddk.log" VDDK initialized without errors. Enabling storage migration for "vm-1466" ... ThumbPrint is: 93:3A:73:B0:76:6C:6C:D8:DF:4C:83:AA:8E:AB:07:5A:FD:44:30:7E Storage migration successfully enabled: "vm-1466" @ "v000ow.pext.ch" Migration is now enabled. De-initializing VDDK libraries. Disconnected from session on vCenter 'v000ow.pext.ch'. Logging out from vCenter 'v000ow.pext.ch' Logged out from vCenter 'v000ow.pext.ch'.
- Backup nachstarten und Ergebnis prüfen
Siehe auch support.emc.com/kb/495114
SAP HANA DB's aufnehmen
Um neue SAP HANA DB's aufzunehmen, muss man durch den Client Wizard durch. Dazu kopiert man am besten eine bestehen SAP HANA DB und passt dann die Einstellungen über "Modify Client Wizard" an (vorher muss man den copy Vorgang abschliessen) :
- Datenbank auswählen:

- Beschriften:


- Groups auswählen:


- Storage Nodes auswählen:
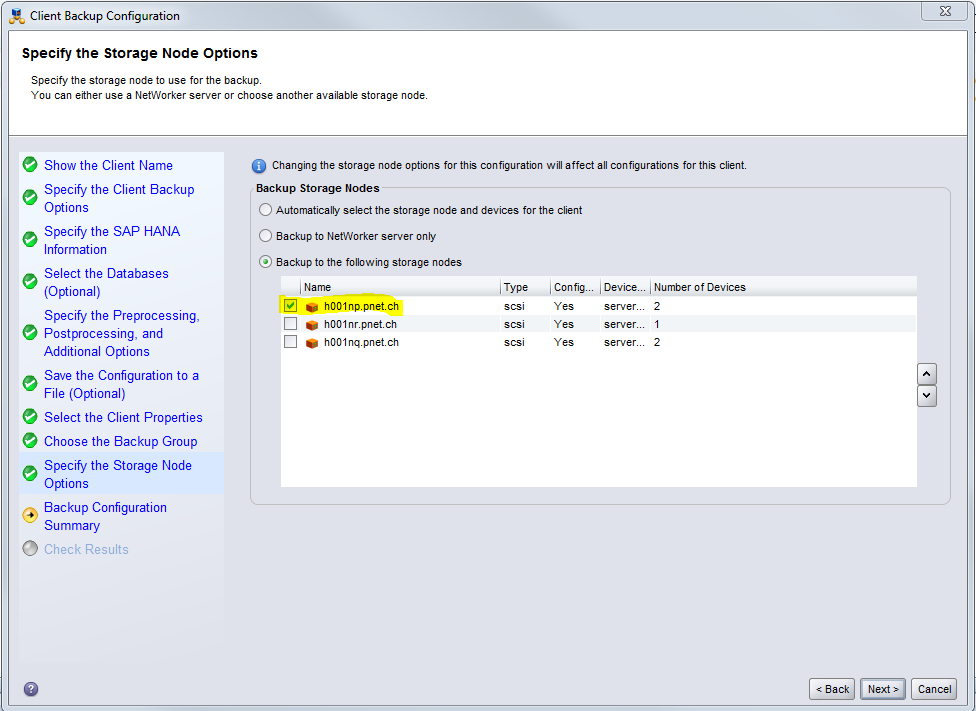

- Symlink erstellen:


- die SAP'er müssen in ihren *.utl File folgende Einträge erstellen:
- Networker Server (h001nr.pnet.ch)
- Media Pool "eh3_hana_bak" oder "zf2_hana_bak"
- Groups "DF_DB_SAP_HANA_ONLY_EH3_4W_1" oder "DF_DB_SAP_HANA_ONLY_ZF2_4W_1"
Restore
Vor dem Restore:
ToDo SAP Team:
- Vorbereiten
ToDo Backup Team: • Deaktivieren der NetWorker Gruppe die die Logfiles sichert (z.B. DF_FS_HANA_ZF2_4W_every_30min_1) Restore: • Neuer Recover Wizard auf der NMC durchführen • Kontrolle Log • Nachricht an SAP Team wenn fertig
Detailierter Ablauf
- Infos von SAP Team
Infos: Beispiel: Server: h00146 Logs von Backup: /hana_backup/log/usr/sap/SH4/HDB01/backup/log/DB_S46 Log Ziel Verzeichnis: /usr/sap/SH4/HDB01/backup/log/DB_S46 Zeitraum: 06.01.2016, 09:30-13:45 (bis und mit aktuellste Log Sicherung (13:30))
- Deaktivieren der NetWorker Gruppe die die Logfiles sichert
(z.B. DF_FS_HANA_ZF2_4W_every_30min_1)

- Neuer Recover Wizard auf der NMC durchführen


Ganzer Pfad rein kopieren! Eine Auswahl via Browser geht nicht da keine Ordnerstruktur da ist.
z.B.
/hana_backup/log/usr/sap/SH4/HDB01/backup/log/DB_S46/

Erstes Kästchen mit der Maus anwählen.
Nun mit der Pfeiltaste nach unten [↓] und anschliessend die [Space] Taste drücken.
Dies wiederholen bis die Liste fertig ist. Viel Spass =).
Unten tauchen die angewählten Files in der Recovery List auf.

Nun den Restorepfad von SAP Team wählen und durch browsen. (Nicht rein kopieren!)
Ok – Next >
Next >
Recovername eintragen (zB. Restore HANA S46 2016.01.06 neuenschwank)
Run Recovery >
evt. Logfile speichern für spätere Fragen
Kontrolle Log
Succeeded … ./log_backup_2_0_50288890112_50289078976.1452075257898 ./log_backup_2_0_50288109696_50288596864.1452071657893 Received 38 file(s) from NSR server `hbeh01.pnet.ch' Recover completion time: Wed 06 Jan 2016 02:07:13 PM CET
Links
Post Intern:
- NetWorker Administration Console
- Lizenzübersicht online in EMC Powerlink
Diverse:
- Original Webseite
- Verzeichnis
- ← Zurück zu Überseite: Backup Infrastruktur